Activation Function 활성화 함수 | (2026-02-21) |
활성 , 소프트맥스, ReLU | |
▷
Top
▷
정보기술(IT)
▷
인공지능
▷
기계학습
▷
신경망, 딥러닝
1. 활성 (Activation) 또는 발화 (Firing) 이란? ㅇ 뉴런이 입력 자극에 반응하는 정도를 의미 - 여기서, "활성화" 되었다는 것은 "발화" 했다는 뜻임 ㅇ 생체 뉴런 - 여러 자극 신호의 합이 임계값을 넘으면, . 활동전위를 발생시켜 다음 뉴런으로 전달 - 활성 강도는, 발화 빈도나 활동전위 변화로 표현됨 . 자극이 강할수록 발화 횟수(주파수)가 증가하는 경향 . 활동전위의 크기 자체는 거의 일정하며, 주로 발화 빈도로 정보 표현 . 시간적 발화 패턴(동기화,간격 등) 또한 정보 전달에 중요 ㅇ 인공 뉴런 - 입력과 가중치의 합 z = w1x1 + … + b가 임계값을 넘으면, . 활성화 함수를 거쳐 출력 생성 - 활성 정도는, 수치로 표현됨 . 출력값의 크기가 뉴런의 활성 정도를 의미 . 가중치(weight), 편향(bias) 등은 학습 과정에서 조정됨 . 대표적 활성화 함수 : Sigmoid, ReLU, Tanh 등 ㅇ (비교) - 생체 뉴런 : 전기적,화학적 신호 기반의 실제 세포 활동 - 인공 뉴런 : 수학적 모델 기반의 계산 요소 - 둘 다, 입력을 받아 임계적 판단 후에, 출력 신호를 생성한다는 공통점이 있음 2. 활성화 함수 (Activation Function) ㅇ 신경망에서, 인공 뉴런의 "활성 정도"를 결정하는 비선형 함수 - 입력값(가중합)을 단순히 출력으로 전달하지 않고, - 비선형성을 부여해 복잡한 관계(패턴, 경계, 구조)를 학습할 수 있도록 함 ㅇ 주요 기능 - 비선형성 도입 → 복잡한 함수 근사 가능 - 출력의 크기 조절 → 안정된 학습 - 확률적 해석 가능 : (시그모이드, 소프트맥스 등) 3. 활성화 함수의 주요 종류 ㅇ 시그모이드 함수 (Sigmoid Function)[# σ(x) = \frac{1}{1+e^{-x}} #]- 출력 범위: (0, 1) . 값이 0 ~ 1 사이로 압축 - 장점 : 출력이 확률처럼 해석 가능 - 단점 : 큰 입력값에서 기울기 소실(Vanishing Gradient) 발생 . 또한, 출력값이 0 또는 1에 가까울 때 학습이 느려짐 - 적용 : 과거, 이진 분류 문제에 많이 사용됨 ㅇ 소프트맥스 함수 (Softmax Function)[# \text{Softmax}(z_i) = \frac{e^{z_i}}{\sum_j e^{z_j}} #]- 출력 범위 : (0, 1) . 각 클래스의 확률값을 출력 - 특징 : 모든 출력의 합이 1이 되도록 정규화 . 전체 출력이 확률 분포 (서로 연관됨) - 적용 : 다중 클래스 분류의 출력층에서 주로 사용 ㅇ 하이퍼볼릭 탄젠트 함수 (tanh) (쌍곡선 함수)[# \tanh (x) = \frac{e^x-e^{-x}}{e^x+e^{-x}} #]- 출력 범위 : (–1, 1) . 시그모이드보다 출력 중심이 0에 가까워 학습이 더 빠르고 효율적 - 단점 : 여전히 기울기 소실 문제 존재 - 적용 : 과거 은닉층에서 자주 사용됨 ㅇ ReLU (Rectified Linear Unit)[# ReLU(x) = max(0,x) #]- 입력값이 0 보다 작으면 무시, 0 보다 크면 입력값 그대로 - 기울기 소실(Vanishing Gradient) 문제 완화 - 적용 : 대부분의 은닉층에서 기본 활성화 함수로 사용됨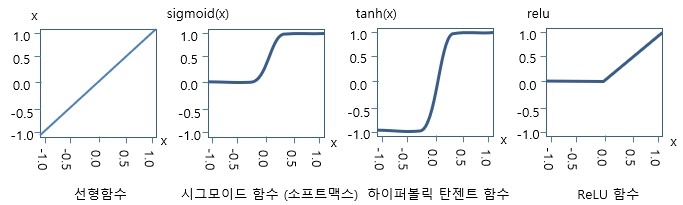
▷신경망, 딥러닝
1. 신경망 (생체 신경망, 인공 신경망) 2. 신경망 딥러닝 용어 3. 인공 뉴런 4. 퍼셉트론, 다층 퍼셉트론 5. 순환 신경망 (RNN) 6. 딥러닝 7. 역전파 8. 활성화 함수 9. 시그모이드 10. 신경망 딥러닝 파라미터 용어해설 종합 (단일 페이지 형태)
"본 웹사이트 내 모든 저작물은 원출처를 밝히는 한 자유롭게 사용(상업화포함) 가능합니다"
[정보통신기술용어해설]